My Experience of Kubernetes Community Days 2022 Chennai conducted by CNCF (Cloud Native Computing Foundation)

In this blog I would be sharing my virtual experience about all the events, keynotes, workshops and activities held at Kubernetes Community days event conducted for a period of 2 days (3–4 June 2022).
To begin with let’s first understand What is a Kubernetes Community Days event?

Kubernetes Community Days event is a community-organized event supported by the Cloud Native Computing Foundation (CNCF) to help grow and sustain the Kubernetes and cloud-native community. It gathers adopters and technologists from open source and cloud-native communities for education, collaboration and networking.KCDs can be in person, virtual, or hybrid. In person is strongly encouraged when possible. Virtual events are run on the Cloud Native Community Groups platform, powered by Bevy.People taking part in the event will be able to participate in quizzes and games and will get a Tshirt as a swag.
What was the Agenda for the inaugural day of the event and what were the technologies discussed?
There were three event tracks to follow designed specifically to three targeted communities (Developer track,DevOps track,& Beginners track).I followed the DevOps track since it aligned with my area of work.
Agenda for the inaugural day included various sessions by experts on new age processes which enable DevOps like Progressive Delivery to workshop on infrastructure provisioning using Crossplane. The Keynote started with a session on Open Service Mesh.I have described below the summaries of the various events topics i had attended.
1.Open Service Mesh — Why, What and How?
In software architecture, a service mesh is a dedicated infrastructure layer for facilitating service-to-service communications between services or microservices, using a proxy.
A dedicated communication layer can provide a number of benefits, such as providing observability into communications, providing secure connections, or automating retries and backoff for failed requests.
A service mesh consists of network proxies paired with each service in an application and a set of task management processes. The proxies are called the data plane and the management processes are called the control plane. The data plane intercepts calls between different services and “processes” them; the control plane is the brain of the mesh that coordinates the behavior of proxies and provides APIs for operations and maintenance personnel to manipulate and observe the entire network.
The service mesh architecture is implemented by software products like Istio, Linkerd, Consul, AWS App Mesh, Kuma, Traefik Mesh, and Open Service Mesh. Many service meshes use the Envoy proxy on the data plane.
OSM runs on Kubernetes. The control plane implements Envoy’s xDS and is configured with SMI APIs. OSM injects an Envoy proxy as a sidecar container next to each instance of an application.
The data plane (the set of Envoy proxies running as part of OSM) executes rules around access control policies, implements routing configuration, and captures metrics. The control plane continually programs the data plane to ensure policies and routing rules are up to date and ensures the data plane is healthy.
The OSM project builds on the ideas and implementations of many cloud native ecosystem projects including Linkerd, Istio, Consul, Envoy, Kuma, Helm, and the SMI specification.
Features of Open Service Mesh
- Easily and transparently configure traffic shifting for deployments
- Secure end-to-end service to service communication by enabling mTLS
- Define and execute fine grained access control policies for services
- Observability and insights into application metrics for debugging and monitoring services
- Integrate with external certificate management services/solutions with a pluggable interface
- Onboard applications onto the mesh by enabling automatic sidecar injection of Envoy proxy
- Flexible enough to handle both simple and complex scenarios through SMI and Envoy XDS APIs
This is the link for a quick demo for OSM’s Key features https://release-v0-11.docs.openservicemesh.io/docs/getting_started/quickstart/manual_demo/
2. Progressive Delivery : New World Old Ways of Testing
If your organization has established an efficient CI/CD pipeline and you’ve made a successful transition to DevOps culture, you probably already understand the benefits of doing DevOps. Your teams share information and collaborate efficiently, and you’ve seen measurable increases in software delivery speed and quality. Aside from continuing to do what you’re doing, though, where do you go from here? How can your teams reach the next phase of DevOps maturity? Once you’re comfortable with continuous integration and continuous delivery practices, the next step is to get really good at progressive delivery.
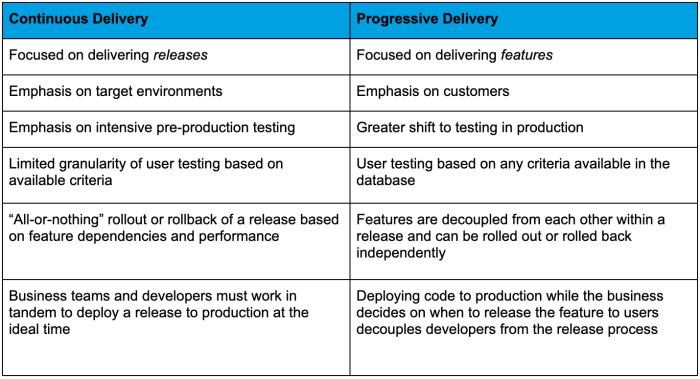
First of all, what’s the difference between continuous delivery and progressive delivery? The goal of continuous delivery is to always keep code ready to be deployed. It helps developers release faster. With more frequent releases that introduce smaller incremental changes, developers can also reduce the chances of things going wrong in production.
Progressive delivery can be seen as an iteration on the concept of continuous delivery. It’s a natural evolution — while increasing release speed and quality is still the end goal of progressive delivery, its focus shifts from the code level to the feature level.
This shift opens up another way for you to de-risk your deployments. With progressive delivery, developers roll out features to a small, low-risk audience first (such as internal QA teams). Features are then released to real users in a controlled, measured manner. This is different from a canary release using standard CD tooling. Developers can gradually “turn on” new features via flags instead of staged deployments — there are no feature branches. Or they can use feature toggles that set up A/B testing to learn which version users prefer.
It’s a repeatable, automated way to test and learn in production based on real user behavior and feedback. Developers can ensure the highest quality code reaches users fast without the risk of releasing to all users at once. This can significantly improve the team’s failure rate, one of the DORA metrics that leaders use to measure DevOps performance.
This chart helps in comparing continuous delivery and progressive delivery.
How do Dev & Ops teams achieve progressive delivery?
To get started with progressive delivery, teams need mature CI/CD pipelines and they need feature flags. Feature flags are a crucial element without them, progressive delivery is impossible. Using the fine-grained controls that feature flags grant at the feature level, developers can test in production on real users with very low risk. If something goes wrong, anyone (a developer or otherwise) can turn off the associated flag and revert back immediately.
This is the foundation of progressive delivery, but developer teams must figure out how to build it into a repeatable, automated practice especially if they need it at enterprise scale. While feature flag adoption is key, developers also need to manage feature flags well in order for progressive delivery to take root and grow.
Tools that enable Progressive Delivery
ArgoCD, Spinnaker, Flagger, Optimizely, Launch Darkly.
Refer the link for implementing Progressive delivery with Argo Rollout https://codefresh.io/docs/docs/ci-cd-guides/progressive-delivery/
Best Practices to migrate from CD to PD
Run the Canary/BlueGreen Deployments for enough times
Carefully choose which metrics to be used for analysis and decision making
Setting up canary deployment is long and iterative process
Use canary reports and their metrics for debugging
Don’t compare against production directly
3. Crossplane : Build and Manage Infrastructure using Kubernetes
Crossplane is an open source Kubernetes add-on that transforms your cluster into a universal control plane. Crossplane enables platform teams to assemble infrastructure from multiple vendors, and expose higher level self-service APIs for application teams to consume, without having to write any code. Crossplane extends your Kubernetes cluster to support orchestrating any infrastructure or managed service. Compose Crossplane’s granular resources into higher level abstractions that can be versioned, managed, deployed and consumed using your favorite tools and existing processes. Install Crossplane into any Kubernetes cluster to get started. Crossplane is a Cloud Native Compute Foundation project.

How Crossplane fares against Terraform in the context of Infrastructure provisioning?
Crossplane is often compared to HashiCorp’s Terraform. It’s common for enterprise platform teams to find Crossplane as they outgrow Terraform and look for alternatives. There are parallels between the two projects:
- Both allow engineers to model their infrastructure as declarative configuration
- Both support managing a myriad of diverse infrastructure using “provider” plugins
- Both are open source tools with strong communities
The key difference is that Crossplane is a control plane, where Terraform is a command-line tool — an interface to control planes. This post touches on a handful of pain points that enterprises commonly face as they scale Terraform, and highlights how Crossplane addresses these issues.
Enterprises often adopt Terraform via their operations team. It’s a great way for a small team of engineers to begin to wrangle their organisation’s infrastructure. Representing infrastructure as declarative configuration allows an operations team to benefit from software engineering best practices-keeping the configuration in revision control where changes can be peer reviewed and reverted when necessary.
Where Terraform can fall apart is when more engineers need to collaborate to manage their organisation’s infrastructure. Terraform relies on a monolithic state file to map desired configuration to actual, running infrastructure. A lock must be held on this state file while configuration is being applied, and applying a Terraform configuration is a blocking process that can take minutes to complete. During this time no other entity — no other engineer — can apply changes to the configuration. Similarly, Terraform uses a monolithic ‘apply’ process — there’s no recommended way to modify only one piece of infrastructure within a configuration. If you use the same configuration to manage your caches and your databases you must always update both — you can’t update only your caches.
Terraform recommends breaking a monolithic configuration up into increasingly more granular configurations. So while the operations team might start with a Terraform configuration that represents ‘production’, they’re encouraged to factor that out into scoped configurations like ‘production billing’ and ‘production auth’. It’s hard to get this right up front, so it can require a lot of refactoring over time, and often results in a complex mesh of Terraform configurations coupled by their inputs and outputs.
Collaboration scales in Crossplane because the Crossplane Resource Model (XRM) promotes loose coupling and eventual consistency. In Crossplane every piece of infrastructure is an API endpoint that supports create, read, update, and delete operations. Crossplane does not need to calculate a graph of dependencies to make a change, so you can easily operate on a single database, even if you manage your entire production environment with Crossplane.
To complement the above events CNCF made it a point to engage and test its community’s K8S IQ with a quiz competition on Kubernetes(the questions mainly focused on the functions of its various components) and to reward those through a lucky draw with a 1000$ voucher credits in Digital Ocean Cloud Provider.
Day 2 Event Highlights: 4th June 2022
1.Keynote : Reliability in Cloud Native DevOps
Reliability means the quality of being trustworthy or of performing consistently well. From a cloud native perspective, reliability refers to how well a system responds to failures. If we have a distributed system that keeps working as infrastructure changes and individual components fail, it is reliable. On the other hand, if it fails easily and operators need to intervene manually to keep it running, it is unreliable. The goal of cloud native applications is to build inherently reliable systems. Since the time DevOps lead the charge in Cloud Transformation,Reliability has opened doors to new practices in how we build reliable and highly available systems and one such practice is — Chaos Engineering.
Chaos engineering is the process of testing a distributed computing system to ensure that it can withstand unexpected disruptions. It relies on concepts underlying chaos theory, which focus on random and unpredictable behavior.
With the rise of microservices and distributed cloud architectures, the web has grown increasingly complex. We all depend on these systems more than ever, yet failures have become much harder to predict.These failures cause costly outages for companies. The outages hurt customers trying to shop, transact business, and get work done. Even brief outages can impact a company’s bottom line, so the cost of downtime is becoming a KPI for many engineering teams. For example, in 2017, 98% of organizations said a single hour of downtime would cost their business over $100,000. One outage can cost a single company millions of dollars. The CEO of British Airways recently explained how one failure that stranded tens of thousands of British Airways (BA) passengers in May 2017 cost the company 80 million pounds ($102.19 million USD).

Why is there the need to practice Chaos Engineering?
Think of a vaccine or a flu shot, where you inject yourself with a small amount of a potentially harmful foreign body in order to build resistance and prevent illness. Chaos Engineering is a tool we use to build such an immunity in our technical systems by injecting harm (like latency, CPU failure, or network black holes) in order to find and mitigate potential weaknesses.These experiments have the added benefit of helping teams build muscle memory in resolving outages, akin to a fire drill (or changing a flat tire, in the Netflix analogy). By breaking things on purpose we surface unknown issues that could impact our systems and customers.According to the 2021 State of Chaos Engineering report, the most common outcomes of Chaos Engineering are increased availability, lower mean time to resolution (MTTR), lower mean time to detection (MTTD), fewer bugs shipped to product, and fewer outages. Teams who frequently run Chaos Engineering experiments are more likely to have >99.9% availability.
2.Kubernetes as Universal Control Plane
Kubernetes is emerging as one of the best control planes in the context of modern applications and infrastructure. The powerful scheduler, which was originally designed to deal with the placement of pods on appropriate nodes, is quite extensible. It can solve many of the problems that exist in traditional distributed systems.Kubernetes is fast becoming the preferred control plane for scheduling and managing jobs in highly-distributed environments. These jobs may include deploying virtual machines on physical hosts, placing containers in edge devices, or even extending the control plane to other schedulers such as serverless environments. Crossplane aims to standardize infrastructure and application management using the same API-centric, declarative configuration and automation approach pioneered by Kubernetes. It is a unified control plane that integrates seamlessly with existing tools and systems, and makes it easy to set policies, quotas and track reports.
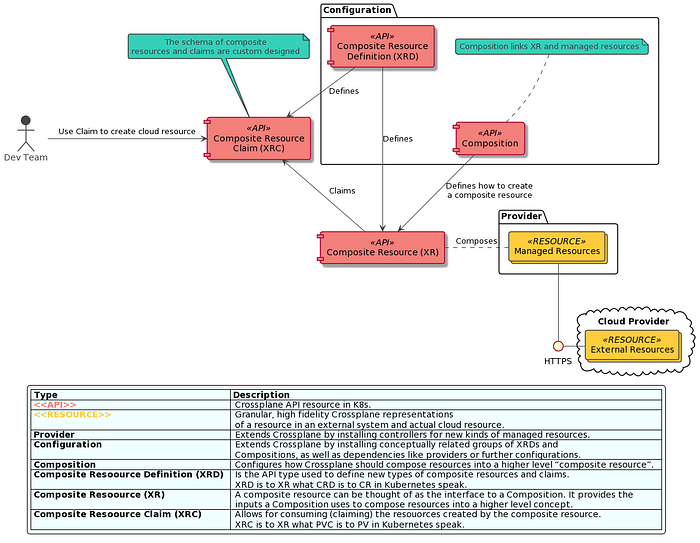
These topics in a nutshell, give you an overview of the kubernetes related technology developments happening now and in the future and i request all my readers to be always on the lookout for CNCF events where you get to know about some open source stuff and engage with like minded folks to grow the open source community because THE FUTURE IS OPEN……
Connect with me on linkedin and follow me for more such blogs on CNCF events, and other DevOps related topics.
